

Machine translation engines trained with translation memory for a specific topic and with specific terminology win big time against stock engines – and are even beginning to surpass human translation for editing purposes.
Seven months ago, I partnered up with Philipp Vein to create Custom.MT – a company that simplifies the implementation of machine translation (MT). The end of 2020 was the pivotal point when MT gained a critical mass in the localization industry and work done with MT exceeded 50% of all work for the first time in history.
We realized MT is rapidly going to become much bigger in the localization industry, and that every team on the LSP side and buyer side would want to implement it. The efficiency gains are just too great to ignore. With the best-quality engine and uniform content, a linguist can work 6 times as fast as a person working old-school in MS Word. Just like with translation memory 20 years ago, the first one to get the best MT wins all the financial benefits.
The challenges with implementing MT are many:
- Find the best engine
- Train models
- Implement in TMS
- Monetize savings
- Improve continuously
In fact, language teams that are serious about MT create specialized departments to nurture and manage their fleets of engines. For example, Acolad and Infor both dedicated 6-person teams to MT, eBay, Electronic Arts, and Lexis Nexis created MT departments, and the list goes on. Custom.MT is an outsourced service that supports either the production team if there is no MT department, or extends the capacity of the MT department in teams that already have one.
In our first months at Custom.MT we attacked engine training, selection and implementation. We designed a Post-Training Evaluation approach to machine translation. While most trainers first select the most suitable engine and then fine-tune it, we went one step further. First, we train 5-7 engines such as Google AutoML, Microsoft Custom Translator, Amazon ACT, ModernMT, Globalese, PangeaMT, Yandex, and compare their performance only after. This way we know the improvement from training across several brands, and we know for sure the best one.
What customized MT brings: quality improves 6–115%
After training and evaluating our first 70 custom engines, we saw quality improvements from 6% to 115%. The quality can sometimes be even better than a human translation. When we run example outputs by a group of three human translators/editors in a blind test, it is not uncommon for translators to pick MT over a sample specialist human translation.
This is what happened with a French to English financial MT engine.
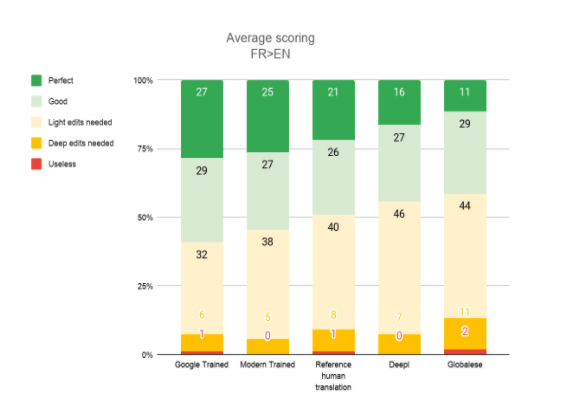
After training an engine with a translation memory of 300,000 parallel sentences, we saw big gains from Google and ModernMT, which attained terminology compliance and offered very sophisticated and accurate language.
The evaluators were astonished:
“Only four segments required real editing; the rest was just like a conventional proofreading task.”
“Very impressive, most 3s and 4s were due to errors in the original.”
In another test, Globalese beat all competitors, leaving them in the dust far behind. We trained a Russian to English engine in aviation. A monster dataset of a million parallel sentences resulted in a 115% improvement to output quality.
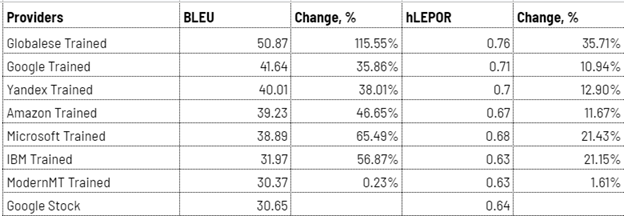
Conclusion? To win the biggest gains, first train, then evaluate. The difference between an untrained MT engine and one trained with a good dataset can be staggering – up to 80–100%.
Which brands to train in memoQ?
memoQ has 21 machine translation technologies integrated directly and 6 of them are trainable via a self-service online console: ModernMT, KantanMT, Omniscien, Pangea, and Google Cloud Translation Advanced. They will be soon joined by Systran; the French machine translation provider is rolling out their studio app to customize models accessible via web API. The Inten.to plugin provides additional integrations to many more MT providers at a cost.
- ModernMT is adaptive MT which learns instantly and is interesting for a continuous retraining scenario.
- Pangea is a flexible Spanish provider with the ability to choose between aggressive and conservative training.
- Systran is a larger company famous for secure on-prem server expertise with many connectors out of the box and the ability to do full-document translation with a TMS.
- Google Cloud is a classic choice because of the sheer number of languages at great quality, but the drawback is that it is a giant company.
Either way, the selection is big enough for most localization programs unless they focus on Asian languages and especially on translations from one Asian language into another, in which case some of the oriental providers like Mirai, Niutrans, and Rosetta offer attractive options.
In our experience, it is more exciting to work with smaller firms. When something breaks down, a small company responds instantly to the alarm phone call, while with an IT giant mobilizing support resources and especially developers is not so simple.
How to convert improved MT to better speed and cost
Quality gains in machine translation are theoretical before they are converted to production efficiencies.
Improvements to speed are automatic once the engine is properly integrated into a CAT tool and the workflow. Improvements to cost are more complex and require a Fair Pay compensation scheme. The idea is to establish a correlation between the compensation and the real amount of work required to polish and enhance MT output.
Compensation schemes for post-editing are pretty new in our industry, and there is no single best practice. Currently, there are four main approaches for monetizing improvements to MT:
- Flat rate discounts
- Per hour payments
- Effort-based compensation
- Mixed
Using these approaches with a tailored engine can lead to savings of 10–60% depending on the content type, language, and the relationship between the buyer and the supplier. Reducing TEP to post-editing only can yield greater savings. A conservative benchmark to cautiously approach budget reductions is at 15–20%.
Feasibility threshold: $60,000 spend per language
We designed a back-of-a-matchbox ROI calculation to get a quick idea whether it makes sense investing into all the training fees, service costs, implementation projects and Fair Pay scheme workshops. The rule of thumb is translation spend of $60,000 or more per language per year.
Here is the formula to make your own calculation.

MT attacks the spend remaining after the application of a translation memory. In most programs, segments with 85–101% matches use translation memory, and anything below 85% uses machine translation.
15% is the average conservative gain from training. To get a feeling how far your efficiency gains will go, look at three factors:
- Language tier: tier-2 and tier-3 languages can benefit more from training
- Type of content: specialized non-creative benefits more from training
- Size and quality of the dataset: 300k segments or more have a greater impact.
If these factors come together, run a pilot training project sooner.
Localization team 2022
I believe that in the next year, there will be numerous changes in translation technology and production setups to adapt to customizable machine translation.
First, the translation management systems and CAT-tools need to improve their readiness for better MT by embedding functionality to correlate MT quality with translation project pricing. They also need to add more support for trainable MT engines: Amazon ACT, Promt and custom Yandex Translator are some of the technologies that need better integration. Localization teams should push their technology providers to bring about these changes faster to simplify adopting better MT.
Second, the tools for the emerging profession of MT trainer will evolve and become more developed, including tools to clean up data, find similar data to enrich datasets, redact sensitive information, evaluate MT quality automatically and with humans, compare engines and predict risk. TMS will add functions to train MT directly from their project manager interfaces.
This will mean that the cost per custom model will go down from thousands of euros today to hundreds tomorrow, while the number of models in each company’s fleet will grow from a handful to dozens and potentially hundreds. There will be fewer translators needed to accomplish the same volume, but more technology and trainer jobs will be created. If your team does not yet have a MT function, it’s time to assign a person, or a supplier, to it.
Where the localization team of 2010 managed 100 translators via a TMS and did zero MT, the 2022 counterpart will have 100 engines operated by 1–3 trainers, and only about 20–24 linguists. That is, unless they decide to triple the volume with the same budget and translate everything into 100+ languages.
Now it has become feasible and manageable – with better models.
