-memoq%20mew%20logo-10.png)
Recently, Angelika Zerfass asked us an innocent question: how exactly does X-translation work in memoQ?
Most of you reading this probably know what X-translation does on a basic level: in place of a translation memory, it uses a previous (translated or half-translated) version of a document to populate translations when you receive a new version of the same translatable document. When you receive the updated version, you reimport it into memoQ, use X-translate to populate what you have translated before, and can focus on the rest. But how does it really work? How exactly does it decide which sentences or segments were changed, and which ones weren’t?
My quick answer to Angelika at that point was that I had no idea and had to ask around or do some research myself. Having done both, I can happily say I still have no idea how exactly it works. I can give you some pointers: start with this Wikipedia article, and if it doesn’t scare you off, also read the other article it links to. You see, it is science. But it is the best kind of science that can miraculously make your life easier without forcing you to fully understand it. You probably have used it many times in Microsoft Word: the same “diff” algorithm is used there to highlight edits of a document using Track changes. The difference is that Track changes highlights changes to a series of characters, typically to show you changes on the level of words, while memoQ looks at changes to a series of segments to translate, identifying the segments that got changed (and not “caring” what exactly changed inside that segment). You can also use memoQ to visualize the segment level differences that are the basis of X-translation, below you can see an example of that.
Forget the science, look at the results
For our purposes, I think it's better to approach X-translate from the practical point of view, and observe its results, rather than the theory behind it. First of all, memoQ does not compare the old and new versions of the documents themselves, rather, it compares the result of the import process: the lists of source segments produced by the previous import and the latest reimport. There is a list of source segments from the original/previous import, and another list of source segments from the reimport. Changes can be of four types: source segments can be modified, added, deleted, or moved. Imagine the two document versions as two column of cells in Excel, with an original version of that column, and a new one that you created by editing the original. Each cell contains a segment. Basically, any segment (cell) that was not modified, added, or moved, is considered unmodified, and will be X-translated if the other criteria are met, according to your options when you clicked “X-translate”. To see what memoQ considered identical, click History/reports, and choose to export a “diff” of the two major versions.
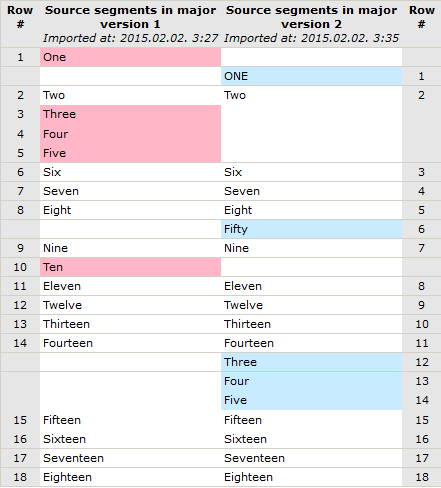
I've done a simple experiment. I started with a text file that contained numbers counting from one to eighteen, each of them on separate lines. This was my original version. I’m showing it “horizontally” here.
- One Two Three Four Five Six Seven Eight Nine Ten Eleven Twelve Thirteen Fourteen Fifteen Sixteen Seventeen Eighteen
Then I modified it a bit: I moved Three, Four, and Five together a bit to the south, modified One to all caps ONE, added Fifty somewhere, and deleted Ten.
- ONE Two Six Seven Eight Fifty Nine Eleven Twelve Thirteen Fourteen Three Four Five Fifteen Sixteen Seventeen Eighteen
The result was that all the other numbers (segments) were considered unchanged by memoQ. Look at the “diff ” report of the two versions:
To get such a report, right-click your document in the Translations tab, and click History/reports. Select the two document versions to compare, and click “Export two-column view of changes”. Purple means deleted, blue means added, and white means unchanged. It’s a peculiarity of memoQ that for the modified first segment, memoQ says the original was deleted and a new one was added, rather than simply telling you it was changed.
And look at the X-translation result (after translating all the numbers in the original to Italian, then reimporting the modified file, and X-translating):


To create this screenshot, I chose the “finished translation” option for X-translation. It can also happen that your updated source documents arrive even before you have finished your first round of translation, and you’d like to seamlessly X-translate and continue working. That’s not a problem: you can use the “mid-project update” option, and X-translate will populate all the translations you have done so far, and keeps your segment statuses and comments intact (together with other useful pieces of information like editing user name, editing time, and the like).
Wait, doesn’t this yield much better leverage than TM?
Originally, I only wanted to discuss how X-translation works, after all, that was what Angelika asked. However, it is also interesting how much better leverage you get from X-translation than from pre-translation from a translation memory (even with context TM), at least in this specific case. All the numbers/segments that were not deleted, moved, added, or modified got X-translated. That is 13 out of 18, or 72%. If instead of X-translation, I confirmed all of the segments of the original version into a TM with context matching turned on, and then I pre-translated the reimported version with that, only a handful of the segments received an in-context (101%) match. That is just 7 segments out of 18, or 39%. The reason of this is that for a segment to be considered an in-context match, the preceding and succeeding segments must be the same as they were in the original translation. And this is “messed up” by any deletion, addition, or modification of neighboring segments.
If you have a previous final translated version of a document and you receive an update, it’s always better to X-translate it as a first step, rather than pre-translate. In our case, assuming that the previously finished translation was reliable, X-translation gives 13 reliable translations that we can trust and lock, and probably do not need to touch or even look at. Pre-translation with context TM would give us only 7. There is a single thing that pre-translation with context TM does better: when there are three or more consecutive segments moved together to another place in the document (like Three, Four, and Five in our case) then X-translation will consider all of them changed. Context TM, on the other hand, will give you a 101% match for all of the segments in the moved “block” of segments, except for the first one and the last one. Therefore it seems the best approach is to X-translate first, and then pre-translate with context TM. In our example, that gives 14 segments filled with “reliable” matches out of 18 (13 or the reliable matches comes from X-translate and 1 from context TM), which is 78%, up from the 39% we get if only context TM is used. I don’t have data to show how well this applies to real life projects, but it is likely to lead to savings there as well. If you do have numbers or insights to share, please do so in the comments below! Also by all means do provide feedback if you see any hard reason not to X-translate when you can.
Could it be better than this?
It must be pointed out that memoQ applies a “basic” diffing algorithm. There are other, more advanced algorithms that could also handle moved blocks of segments. If that was implemented in memoQ, we could go even higher with leverage than what is currently possible, with fewer manual steps to be performed: memoQ could simply identify the moved block of Three, Four, and Five, and X-translate it. There is also an opportunity on the LiveDocs side: even though LiveDocs allows you to keep corpora of your previously translated documents, you cannot use them for X-translation, you can only use them for “traditional” pre-translation. This means that project managers who want to realize the benefits of X-translation must move documents around from old projects to new ones using bilingual exports and imports, or keep reusing the same project. (Because X-translation in memoQ requires a document to be reimported.) If memoQ could automatically identify the previous version of your current document in your LiveDocs corpus and X-translate from it, that would be something real wonderful. I’m just hoping Gábor Ugray is still reading.