

Regular expressions in memoQ are a powerful means of finding character sequences in text. Learn from Michał Tosza, through his struggles and successes, on how to effectively use regex in memoQ!
I may know a thing or two about memoQ in general, but the sheer number of functions and the myriads of options available are still a bit overwhelming. But that’s OK. I do not have to know every tiny checkmark and radio button, as long as I am aware these settings are there if needed and I can open help files or Google to check how to use them. Regular expressions are a perfect example of this. I know they exist. I know what they do. I know they are amazingly useful. Yet, whenever I need to use regex, nothing works. I envy my great fellow experts Marek Pawelec and Kevin Lossner who are fantastically fluent with regex. My regular expressions are clumsy, painful to come up with and creating them is time-consuming. But this does not matter, because the most important is that even poor regex can save hours of work, ensure higher quality and make your irritation level a lot lower.
About regular expressions
If you did not come across regex before, the brief definition would be: symbols describing text patterns that are used to match, search and manipulate text. Regex is „search and replace” on steroids. What is very rarely added when describing the usefulness of regex in CAT tools – that when a regex rule finds a pattern, it can be displayed in a view and worked on, or can be tagged, or can be filtered, etc. Using regex to find texts is one thing, what I believe is much more important is that you can do a lot of operations on the found texts. There lies the power of regex. Yet, this still sounds like a definition and theory. I don’t prefer definitions and theories, so have a look at this localization file from the game I recently translated - Youtubers Life (to import it correctly to memoQ see my other post).
Raiser Games case study
Raiser Games is very nice and allowed me to use their real strings in this post.
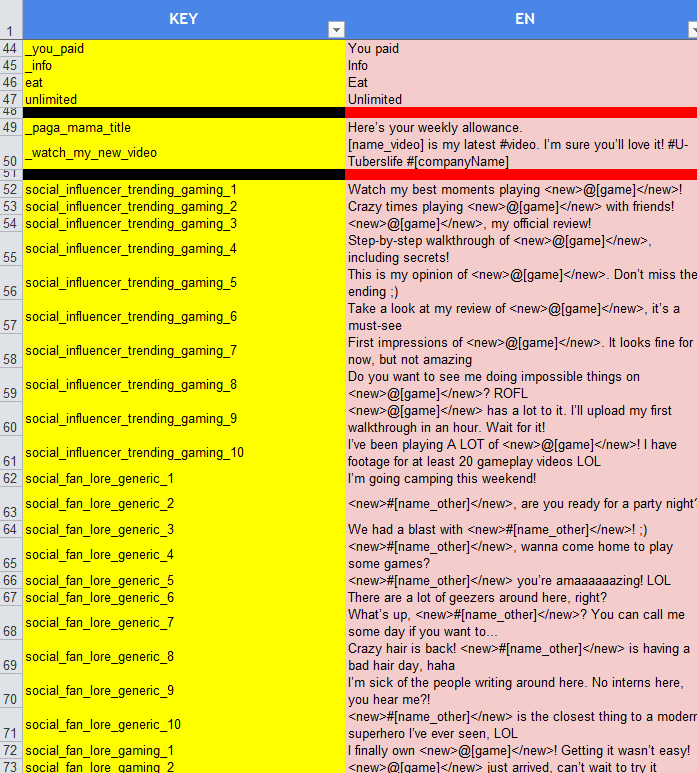
The strings are full of diverse placeholders: <new>, @[game], #[name_other] and some other, Moreover, the placeholders pairs can contain normal words within them or other placeholders. It is obvious you need to have all the placeholders in your translation, as they depict titles of games and names of characters in the game. What is more – placeholders are unusual texts string, different from “normal” words, and they are very prone to spelling issues. Even worse – these spelling errors are undetectable because spellcheck engines would not know, what a correct placeholder should look like. And the worst is that there are literally thousands of them in the string list and even a single missing bracket or slash can make the whole placeholder unusable. That is why typing placeholders by hand is not an option.
Can regex help here in any way?
Here are 3 different regex ideas I had when I was preparing to localize this game:
1. My first and poorest idea – I used regex to filter out only the segments that contain placeholders and wanted to translate these strings first.
GOOD:
I know that each segment currently displayed in the view does contain at least one placeholder and I will not omit any of them, so I focus on this and painstakingly translate all of them by hand.
BAD:
- Segments are out of context.
- Source placeholders must still be input/copied manually to target.
- Not much help in protecting placeholders, but at least I could display all of them and see how many of them there are.
To use this method I created a basic regular expression that displayed ALL the placeholders – and since every placeholder contains “<” or “[“, then the regular expression must say exactly this “display segments that contain < or [“, and this regex would be:” \<|\[“ (no quotes used in the regex itself). Backslash says “treat the next character not as a special regex character, but as a literal character”. And with all its simplicity it worked! Nonetheless, it was useless, due to the reasons above.

2. The other solution was a bit more elegant – I did not want to display segments with placeholders, but to mark each placeholder in each segment as a memoQ tag during importing the XLS file to my project. Placeholders converted to tags would give me 100% certainty I would not mess up or forget any placeholder, and I could even run a QA test for missing or incorrectly placed tags. This started very nice – having clicked Import withoptions, I picked the XLS file and used Multilingual delimited text filter, then I configured the columns and via Add cascading filter I added Regex tagger filter.

Yet, it occurred to me that the file (it was huge – more than 45,000 words and almost 5,000 strings) contained way too many DIFFERENT placeholder types. It would be counterproductive to scroll the strings in Excel (as there is no preview in Document import settings) and look for all the types.

My previous simple regex rule would not work here, as now I did not want to display all SEGMENTS containing placeholders, but to identify ONLY placeholders within all segments. So this idea failed as well. But its basis was good.
3. The final solution that would give me satisfying results and which I was able to implement was to:
- import the XLS the standard way with Multilingual delimited text filter,
- start translating the strings,
- use Regex tagger whenever a placeholder is noticed and try to compose a regular expression that converts this placeholder with all its repetitions to tags.
How to proceed with the last solution (remember – none of the below regex rules should contain quotes when inserted in memoQ)?
- Start translating and reach segment 5 (1) containing the first placeholder – [n].
- Click Preparation tab (2) -> Regex Tagger (3).
- In Tag current document dialog click in Regular expression field (4) and create your first regular expression:

- type \[n\] and click Add button (5) and mark Empty radio button (6) in Tag type section, as this is neither opening or closing tag. If this works, the Results window (7) below should display <[n]> in red font. Congratulations – all [n] placeholders can now become tags. But now you notice, that just 4 segments below (number 9) there is a [param2] placeholder (8). It would be nice if the same regular expression you just created could convert this placeholder to a tag as well. [param1] should also easily fit in the same regex.
So:
- you would need a regex that says “if a placeholder starts with [ then has any letters, numbers or other characters and ends with ]”, convert it to a tag.
- click Pattern button (9) by the Regular expression field for some inspiration and start experimenting. “\[.\]” would be a good idea, as period means “any character” no matter if this is a letter, a number or anything else. However, after clicking Change button, it highlights [n] only. Why? Because one period in the regex means “only one character”. OK, so let’s make it “\[.*\]”, as asterisk means “one or more”. Looks promising, but in segment 13 you notice that a part of the text will become a tag. Your regex rule is too “greedy”, time to limit it with “?” and create “\[.*?\]”. That works – all placeholders of type “[anycharacters]” will now become tags.
- do not click OK yet, as just below there are <new> and </new> placeholders. Add next rule: \<.*?\>. Test it. It works but is not elegant. Why? Both placeholders (<new> and </new>) are converted to tags, yet one of them is opening and one is closing. memoQ gives an option to differentiate them, so let’s do it.
- there are many ways to do it, but the simplest that came to my mind is: \<[a-z]*?\>. This says “if there is < followed by any small letters and ends with >”, convert it to tag. Notice, it does not catch </new>, as / is not a small letter. If you like this rule, mark it as Open in Tag type and click Add.
- the rule for </new> would be then “\<\/[a-z]*?\>”.
- Click OK, to see the results.
This worked like a charm, even with my poor regex skills. Notice that even placeholders such as [console_name] are neatly converted to tags.
What are the benefits of using regex in this file?
1. No broken or missing placeholders in translation. They are converted to tags and are safe and QUICK to copy/transfer from source to target.
2. QA engine catches any forgotten tags. It would not work with placeholders in text form as they were.
3. You can translate faster, as no placeholder requires manual typing.
4. You can deliver higher quality, as breaking the placeholders converted tags requires a REAL dedication.
5. One thing to look out for: you are not proficient with regex and you noticed regex is “greedy”, so after implementing some regex rules pay attention if they did not catch too many phrases/characters as it happened in the example above.
By no means I used the best and most effective regex rules here, but as mentioned in the beginning of this post – that is OK. I do not have to be an expert Regexer to use this feature. This is not as advanced as it seems. And even with the simplest regex rules, the results can be amazingly useful. Use poor regex – it is way better than not using it at all!
