
.png)
I must confess I always felt like an impostor; I have been localizing games for quite some years now, but I am not familiar with how they are created – meaning developed. I do know a great deal about the general approach to software development, but I have actually never taken part in the development of a game.
Several weeks ago, while browsing the Internet, I came across a fantastic resource created by Scott Lilly. He developed an introductory C# course where he teaches programming based on creating a very simple RPG game. I did not hesitate to try it myself!
A few hours later, I was already creating my first game while at the same time learning a bit of C#. A few days into the project, I realized that Scott's course was too good to be available only in English. So I sent him a message. After a few emails, he agreed to help me localize his course into Polish. If you follow me on Twitter you will see this is actually happening now: I am learning C#, developing my RPG game, and localizing the course.
After having started the translation of the course, I reached out to Scott once again to see if I could use his course for the purpose of this article. It was a perfect match because it is about games, has many files, features a lot of repetition and chunks of source code, and most important of all, I have used many different "flavors" of sorting and filtering for this job. Therefore, all of the examples and features described below are actually real case scenarios I used when translating this course.
If you have a good memory, you will probably remember a few weeks ago I already introduced you to this pair of functions in the post: Localizing games in memoQ: 5 useful features. Let me introduce you a few more strategies on how to use them when translating huge projects.
Let’s get started
Once you import the course files (download here), you will notice this is a serious job, as it contains more than 64,000 words in 57 files.
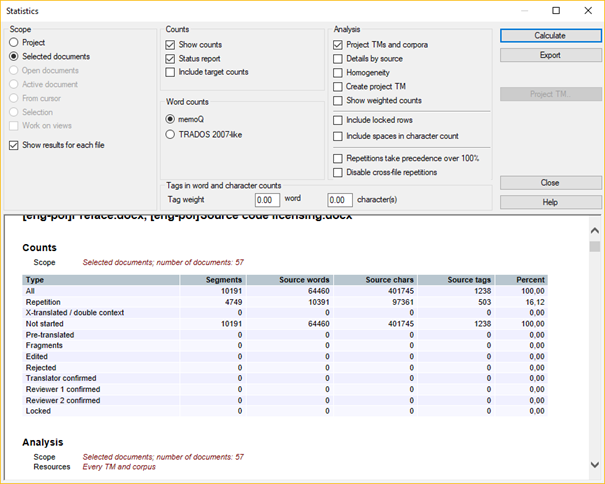
A piece of advice: Do not get overwhelmed with the number of words at the beginning of huge projects! Just try to "get rid of them” as quickly as possible. Below I will show you how the sorting and filtering function in memoQ can help you achieve this.
I have already created a view of all files and browsed them. At first sight, I noticed that Scott placed a lot of source code in his lessons.
As a basic localization rule of thumb, source code will not be translated.
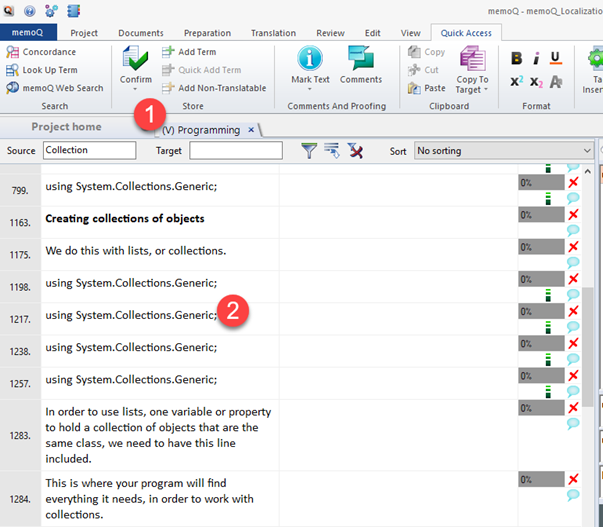
On a regular project, I would just copy the source code to my target translations, but doing such thing for this project would be irritating given the amount of the code is overwhelming. What is more, source code contains "real" words. So when I was looking for terminology usages and context with "Source/Target" filtering fields in memoQ (1), source code fragments tended to pop up (2) constantly. I did not want that, as such context is not helpful at all. See below the filtering search for the "Collection" term, after which I decided to prepare this job again, from scratch.
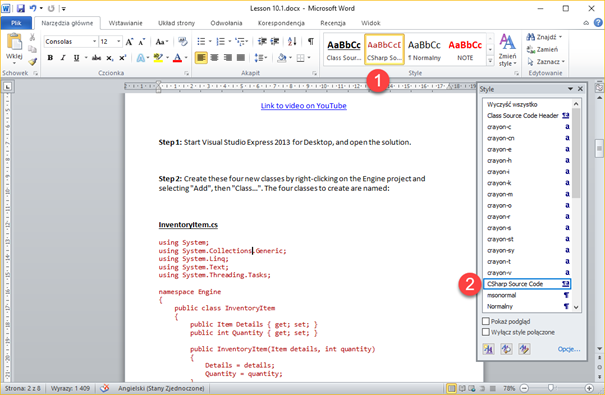
1. To remove source code completely from the translation editor, we needed to re-import the course files, and instruct memoQ not to import source code. This is fairly simple, as all source code is neatly formatted as "CSharp Source Code" (1), (2).
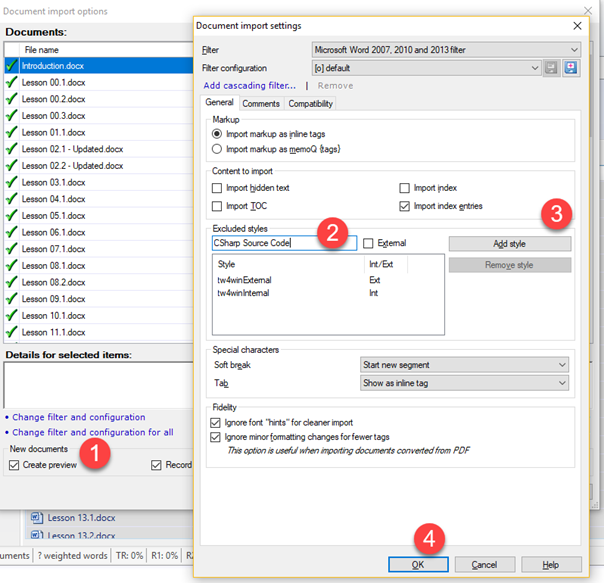
2. When re-importing the files, click Import with options. In the Document import options dialog, click Change filter and configuration for all (1). In the Document import options dialog, just type the style name “CSharp Source Code” (2), click Add style (3), and then, OK (4).
3. Now, filtering for segments containing the term "Collection" gives only relevant segments, and all the source code is gone from the editor.
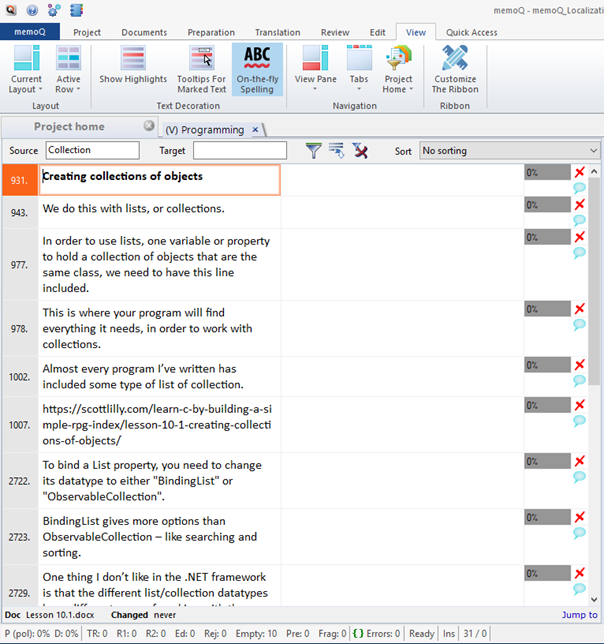
You may think: What about the context? If I can’t see the source code, I could mess up my work! Although it is non-translatable, it is vital for executing my job properly. You are definitely right! But even if the source code is now invisible in the Translation editor, you can still display it in the Preview pane.
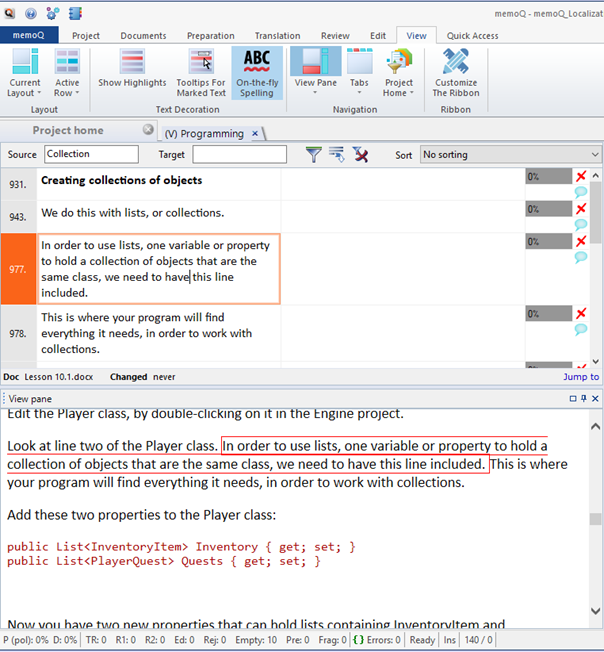
As you can see, it all started with a very simple action: filtering for a term. But then, we ended up re-importing the whole job, cleaning up imported files, and getting the best of both worlds: source code does not bother me anymore, and it is still available in the Preview pane.
The source files were imported properly, so let's start to translate. As soon as I started translating, I realized the course has many files, and each one is named a "lesson". Therefore, there was a big chance that some introductory sentences or endings were actually the same for all courses - what we know as repetition. So I clicked Sort drop down list and sorted the segments by Frequency (higher first). "Links for this lesson", "Summary" and "Step" were the most frequently used segments. I regarded safe to translate them all the same way, as there is only a small chance the context of these repetitions might vary. So I translated one of them and then used the auto-propagate function to populate all of the other segments.
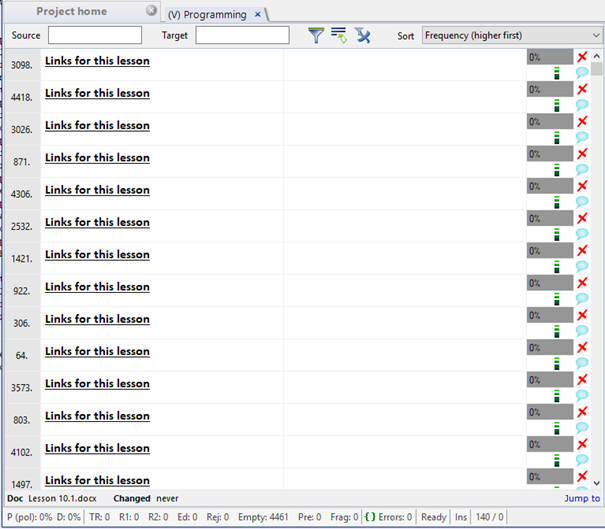
Start to translate these repetitions, and you will soon notice there are many more of them (such as "At the end of this lesson, you will know…", "Lesson Objectives" or "Note").
We can regard all of these as safe to translate. Now, check the bottom of the window, and you will realize you have already completed 2% of the project.
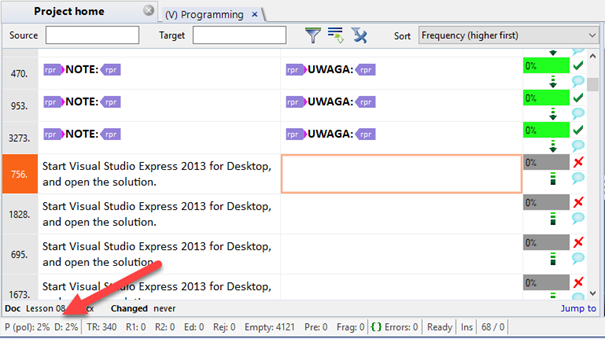
Now, let's click the Sort drop down again, pick No sorting, and revert standard sorting. I know the segments I have already confirmed will not change - they are short and easy, and will not even require proofreading at the end of the day. So I will proceed to lock them all. The easiest way of doing this is to filter (1) all segments with status (2) Confirmed (3) - see image for reference.
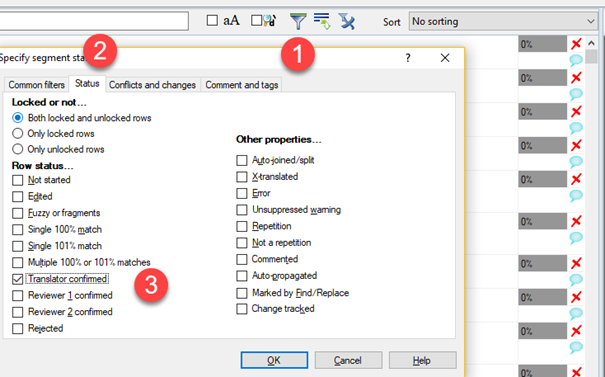
Now I click the Preparation ribbon, and then the Lock/Unlock segments button.
I think you will agree with me: we got rid of many words without much effort. The good news is there is still more we can do to speed up work. Let us now check segments containing only numbers. I believe it is safe to translate these at the beginning of the project as well - but it always depends on your particular project. Let us mix several features of sorting and filtering to quickly translate (or rather copy to target) all segments containing only numbers.
The Source/Target fields we previously used are useful tools, equipped with case sensitive search and regular expressions - I will write about the latter in a future article. For the moment, let's just say that regular expressions are very powerful search functions that allow looking up for almost any kind of text you can imagine. In this example, I will use a basic regular expression that finds all digits in all segments.
1. Check the small box with a magnifying glass and a letter "d" (1), then in the Source field, type [0-9] (3). This tells memoQ to activate regular expressions, and look for all segments containing any digits from zero to nine.
2. Press Enter or click the icon next to the funnel.
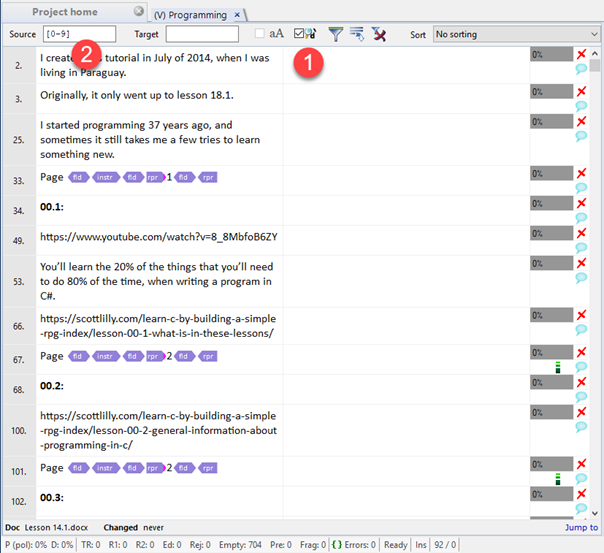
The regular expression has now filtered the segments. As you can see, all of them contain numbers - but you will also notice that these segments also contain text. So how do we proceed?
We only want to translate segments similar to 34 or 68. 3.
So let us change the order of the segments, and sort them alphabetically. You will see this helps us a lot. Click the Sort drop down list (1), then pick Alphabetical by source (A -> Z) (2).
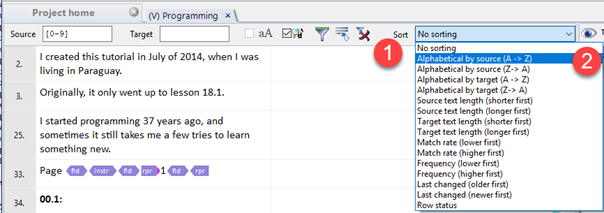
4. The order of segments has now changed. Now, scroll from the top to segment 34. Below it, you will find segments with numbers starting from 0 to 9, just as in the regular expression we used.
5. Now just click the number of the first segment containing digits (#34) and scroll all the way down to the last one (#4422). Hold the SHIFT key and click segment 4422. Segment numbering looks tricky now: it still shows where the segment was in the view we created at the beginning. So you did not mark almost 4400 segments (34 to 4422), only 128. Right-click and choose the Copy Source command, hit Ctrl+Enter and all 128 segments are confirmed. You can also lock them, if you wish.
A Piece of Homework for you!
There is an error with my method above. Are you able to spot it and say why this “filtering and sorting for numbers” method would not work as I expected?
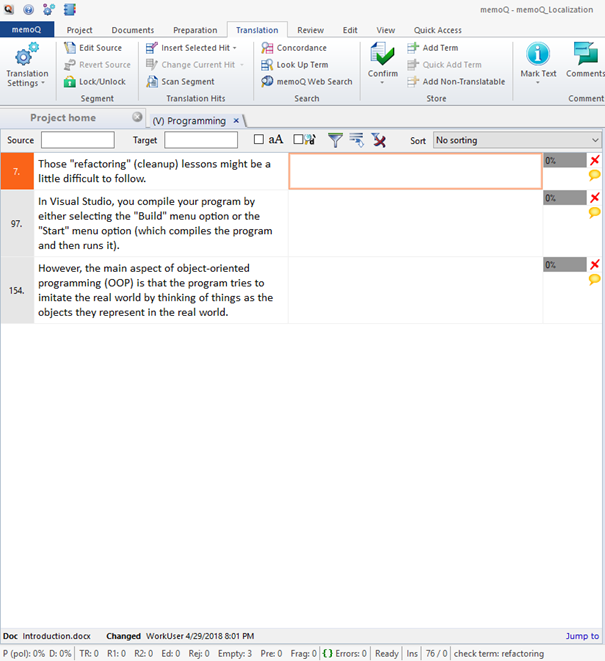
As mentioned before, I have never developed games before, so some of the terminology Scott created was a mystery for me. I did not feel like mining for every single term, so I decided to mark suspicious terms and ask Scott for clarification. To do this, I used comments feature in memoQ. Adding comments is easy, but finding the commented segments later is less so. Fortunately, filtering helps us here, too. Pick a segment, press Ctrl+M, add the comment "check term", and press Enter. Repeat this in 3 random segments.
To find the commented segments in memoQ 2015, follow these steps:
1. Click the funnel icon.
2. In the Specify segment status dialog, click the Comment and tags tab.
3. Type “check term” in the Comment contains field, and press Enter. (Note: this procedure finds only those segments that have the “check term” comment.)
In memoQ 8 and newer:
1. Click the funnel icon.
2. In the Advanced filters dialog, click the Status tab.
3. Under Other properties, check the Commented/Discussed checkbox, and click OK. (Note: this procedure finds all segments that have a comment.) Only the 3 commented segments are displayed.
This way I was able to prepare lists of queries in batches. To return to displaying all segments, just click the “funnel with an X” button.
What I especially like about filtering and sorting is that the two features cooperate smoothly. Here I list a few ways you can leverage their potential:
- Filter segments for a term, and sort the displayed items by segment length.
- Add regular expressions and case sensitivity to a filter to achieve extremely accurate results for your search.
- Use the "Last changed (newest)" sort option to display the last segment you worked on, whenever you need to come back to a project that you left several days ago.
- Combine multiple filters. For example filter for segments with the term "potion", then filter again, for the term "inventory". You will get sentences containing both words: potion and inventory.
- Pre-translate the text, filter out only Pre-translated segments, sort by Match rate (higher first) and confirm all 100% matches (if there are any, and you are certain of them).
- Look for all the segments with "hlnk" tags, display only segments that contain hyperlinks and check if the addresses are correct.
- Pick the Unsuppressed warning status for filtering, and see only segments marked with QA issue lightning icons.
